A Journey Towards a Custom Data Warehouse Solution
Part 1: Getting Started
10 minutes read
This is part one of a series of articles in which we would like to share our journey and our experiences towards a custom data warehouse solution. Part one starts with a brief introduction to upday including the types of data we work with and a description of our working environment. Furthermore, we come up with a tentative definition of a data warehouse (DWH), describe components regarding our use case, and identify tools which can be applied for implementation. Finally, we introduce a data lake as a more ‘Big-Data-friendly’ but provisional solution.
upday And a Huge Volume of Data
upday is a news app which aggregates content from thousands of sources including trusted brands and bloggers into a unique and simple format. It is available in a variety of European countries in a wide range of languages. upday is designed to be an intelligent news aggregator which learns about the reading habits and preferences of each unique user. For that reason, we have to cope with a huge volume of incoming data from a vast number of sources. For example, we handle the following types of data:
- Content metadata such as information about the content type, the publisher, and the publishing date is amongst others used for maintaining the publisher relationship. Content metadata is semi-structured but also contains unstructured data such as a title, a description, and the content itself e.g. in text form.
- User preferences are reading interests explicitly selected by the user and are used to personalize the content we deliver to the user. User preferences data is a form of structured data.
- User behavior includes information about the content consumed by the user and is used to improve the users’ experience with our product for example by means of collaborative filtering. User behavior data is also a form of structured data.
All personal data is considered confidential and stored anonymously. It is impossible to identify individual persons based on the collected data and, of course, we do not pass personal data to any third parties.
upday itself is a startup and a dynamic working environment with an agile development process. We use cloud services in order to avoid the commitment and costs of purchasing hardware products. This enables very fast development, allows us to perform cost efficient short-term experiments, and to pivot directions quickly.
DWH – A Tentative Definition
Every beginning is hard, and we certainly did not know where to start. Thus, we asked ourselves; What is a data warehouse (DWH)? We decided to start with the first use case we could already see ahead of us. As stated by Inmon:
“A data warehouse is a subject-oriented, integrated, nonvolatile and time-variant collection of data in support of management’s decisions.” 1.
A more natural definition is provided by Kimball:
“A data warehouse is a copy of transaction data specifically structured for querying and reporting.” 2.
However, these definitions are still very abstract and did not help us a lot to understand what exactly to start with. In our minds, and from a historical point of view approximately 5 - 15 years ago, the domain of data warehousing was marked by products from big companies like Oracle, IBM, or Microsoft. Usually a product provided by one of these vendors was installed on an expensive server farm. This infrastructure was then used to create a multidimensional data cube which was continuously and automatically processed overnight. This was generally very expensive, highly inflexible, and lead to a strong product-customer dependency. It is easy to assume that it is complicated to change such a production-ready DWH solution after it is been established. We were wary of getting caught in a situation like that.
But as we know, information technology is a vibrant area and rapidly changing. In recent years, the possibilities for data warehouses and even data management platforms have changed dramatically. Since we were not familiar with state-of-the-art techniques and best practices of building a DWH, the amount of possible products and solutions was overwhelming. Therefore, we decided to engage a consultant with domain expertise to guide us the first steps.
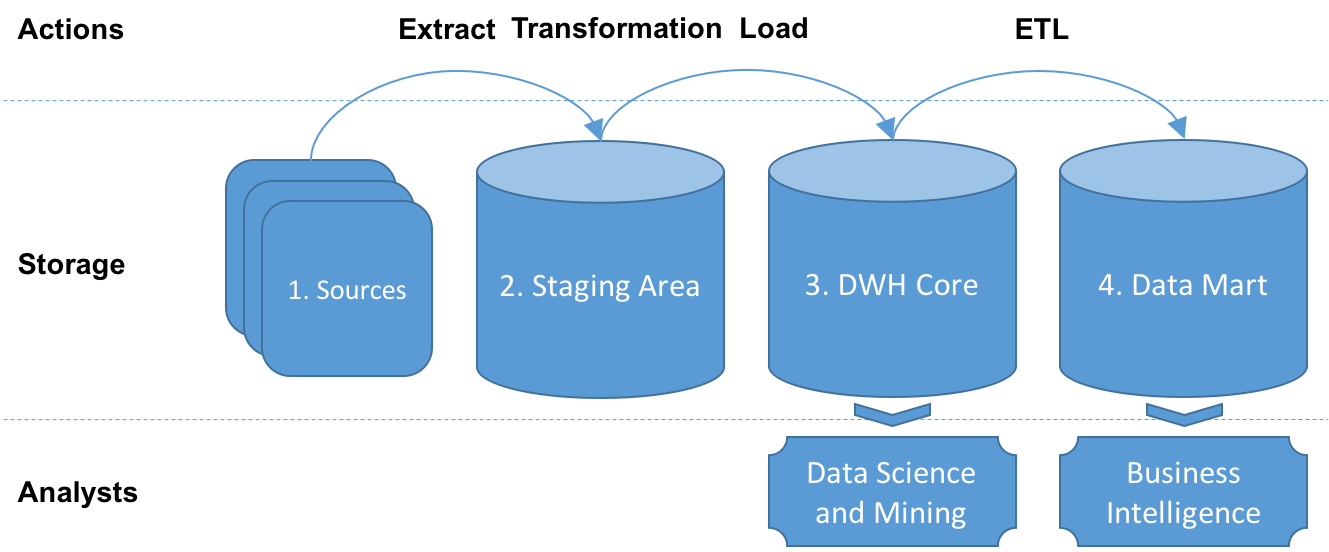
Basic Components
In collaboration with the consultant, we identified basic components of a DWH for our use case: sources, staging area, DWH core, and data mart. The points and diagram below describe these components:
- Sources: We already introduced three types of data in the first section but we did not mention the data sources. The content metadata, in agreement with the content publisher, is usually directly extracted from the publisher’s source and stored into Elasticsearch. Data about user preferences is provided by our own in-app service and stored into a PostgreSQL database. User behavior data is both collected by our own in-app service and by a third party service. User behavior data is then stored into an S3 bucket.
- Staging area: The staging area is the first destination of all the data. It contains data which was extracted from the sources and might be incomplete and unadjusted. This location can be used for data cleansing and transformation.
- DWH core: It is planned to load the cleaned and transformed data into the DWH core. The DWH core is intended to contain the entire data for general purpose analysis. This contrasts the previous definitions which describe a DWH as subject-oriented. We wanted to keep that door open because analysis purposes were not clearly defined at that stage and keeping the platform flexible was important to support comprehensive analysis by data scientists and data mining experts.
- Data mart: For our use case, the data mart is the business layer which is subject-oriented and optimized for analysis purposes. The data is loaded from the DWH core via a separated ETL process and contains aggregated information which can be queried by business analysts.
Processing Steps and Tools
From the consultancy, we learned that a DWH can be implemented as a flexible process chain which is applied to collect data from different sources. The collected data is then stored in a central location and used to generate reports, create insights, and support business decision-making. We identified the following process steps: extract, transform and load (ETL), scheduling, monitoring, storage, and reporting. As briefly described below, each of these processing steps can be covered by a variety of tools:
- The ETL process is one of the most important processing steps of the DWH. It is applied to extract, transform, and load data from various sources into the staging area. Available ETL tools are: Talend, Etleap, Alteryx, Pentaho, and AWS Lambda.
- Scheduling is used to trigger specific actions time-controlled. For example, it is useful to execute long running and complex calculations overnight and not during the main business hours. Another example is consecutive actions where one action waits for the successful termination of another. Some scheduling tools are: Jenkins, Talend Enterprise, and SOS-Scheduler.
- Monitoring is required to be informed about the condition of the DWH and the states of individual actions. It is crucial to be alerted automatically in case of problems. Possible monitoring tools we identified are: Splunk or DataDog.
- Storage is mandatory for a data processing where the data is persistently accommodated. Some available storage tools are: Redshift, Snowflake, PostgreSQL, and Cassandra.
- Finally, reporting is the purpose of a DWH where, based on the data held in the DWH, business cases are summarized and visualized.
Data Lake – Why Would We Need One?
We have already gained a few million monthly unique users and it seems that this number will keep growing. Thus, our data management process is clearly within the realm of Big Data. However, relational database systems are usually not well-suited to handle semi-structured and unstructured data as we have to deal with. Consequently, we also discussed a more ‘Big-Data-friendly’ solution which is known as a data lake 3. Stein and Morriso describe a data lake as follows:
“A repository for large quantities and varieties of data, both structured and unstructured.“ 4.
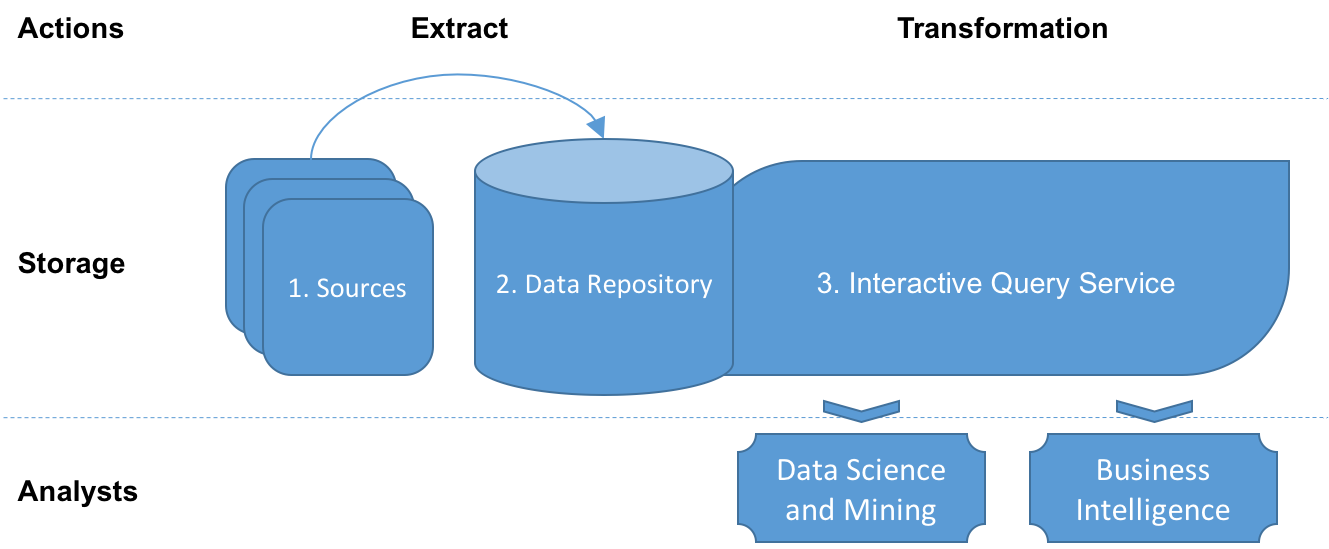
Based on this definition, a data lake solution could meet our needs perfectly. We have looked at this topic more closely, conducted further research, and defined the following components of a data lake: sources, data repository, and interactive query service. The points and diagram below describe these components.
- Sources: As described earlier, we have to deal with structured, semi-structured, and unstructured data.
- Data Repository: This is used to store the data heterogeneously. It preserves the original data fidelity extracted from the sources and the lineage of data transformation.
- Interactive Query Service: This is a service which accesses the data repository and transforms the data into a format that can be consumed by data science, data mining, and business intelligence experts. The interactive query service can be a transformation rule which defines how to transform the data. This transformation rule might be used to store the results persistently into the data repository or into another data base. It can be also used for exploring the raw data.
Adaption of Processing Steps
The data processing steps are similar to those described in the process chain above and are still valid regarding the data lake approach. In our use case, we adapt the process chain in two main ways: storage and interactive query service.
- Storage: For this use case, S3 and HDFS are appropriate storage solutions.
- Interactive Query Service: Query tools can be Hadoop, Spark, or Amazon Athena.
Summary and Outlook
In this article, we briefly introduced upday as an intelligent news aggregator and described the data we deal with. We identified basic DWH components and processing steps regarding our use case. We also discussed a data lake as a more ‘Big-Data-friendly’ solution.
Stay tuned for the next blog posts where we will describe the first iteration of our DWH implementation and express the selection of tools. Moreover, we will explore the evolutionary development of the first DWH implementation and the experiences we gained during this period including trials and mistakes we have made.
References
-
W. H. Inmon. Building the Data Warehouse. John Wiley & Sons, Inc., 2002. ↩
-
R. Kimball, Mary Ross. The Data Warehouse Toolkit. The Complete Guide to Dimensional Modeling. Wiley, 2013 ↩
-
D. Woods, Big Data Requires a Big, New Architecture, Forbes 2011 ↩
-
B. Stein and A. Morriso, The enterprise data lake: Better integration and deeper analytics, Technology Forecast 2014 ↩